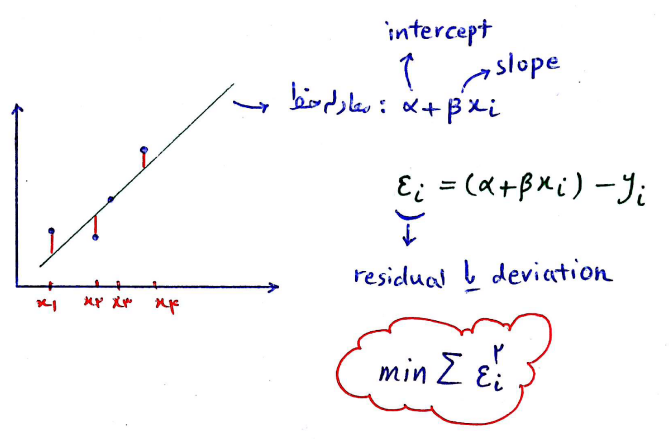
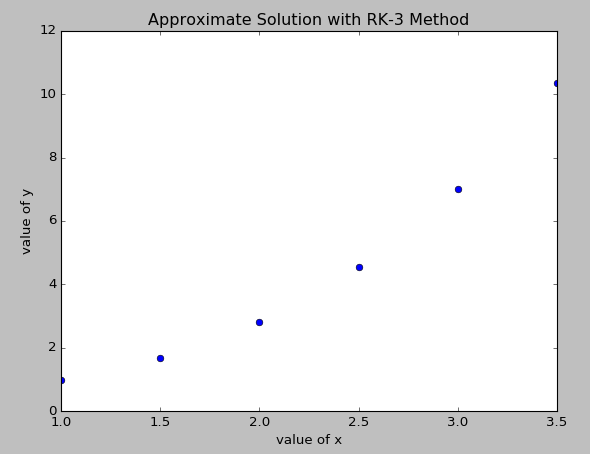
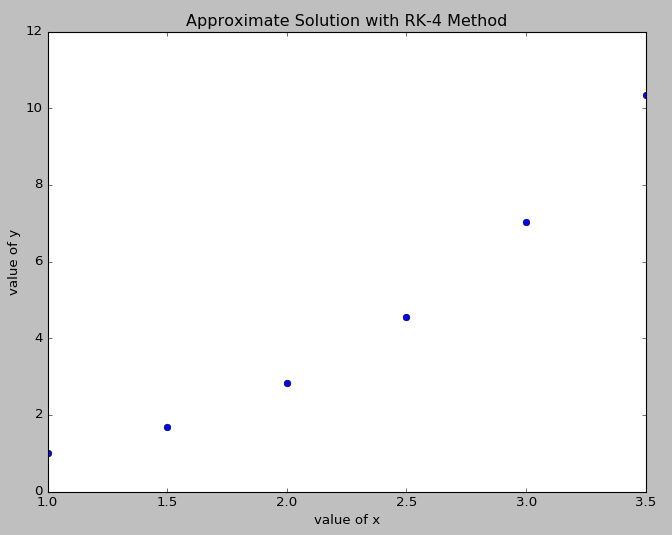
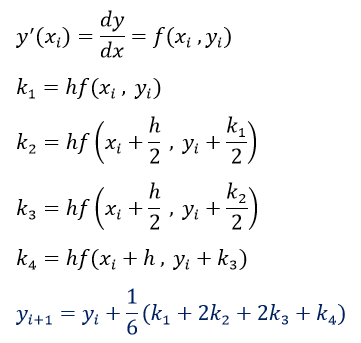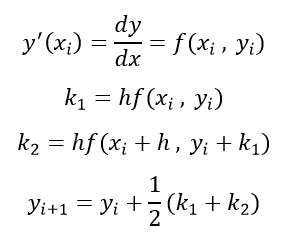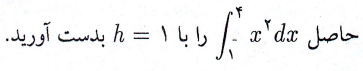تابع خطا (Error Function) در ریاضیات، تابعی غیراصلی (نداشتن ضابطه صریح) است که در علوم احتمالات، مواد، آمار و معادلات دیفرانسیل با مشتقات جزئی استفاده میشود. تعریف این تابع به صورت زیر است (منبع: ویکی پدیا):
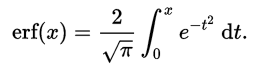
همچنین متمم تابع خطا (Complementary Error Function) نیز به شکل زیر تعریف میشود:
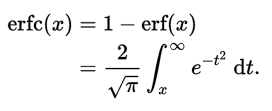
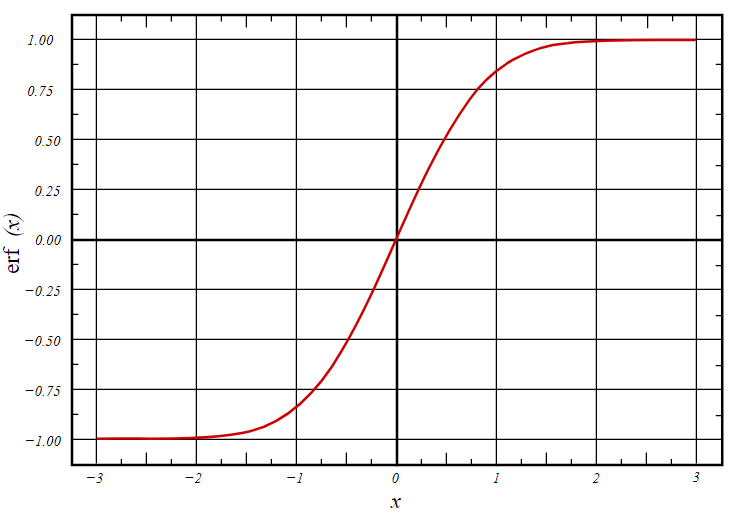
نمودار تابع خطا
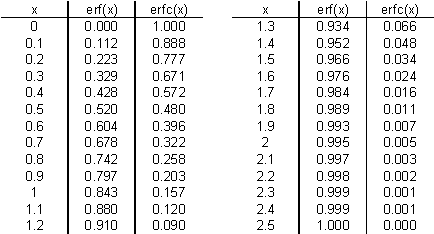
جدول تابع خطا
علاوه بر اینها، در زبان برنامهنویسی پایتون نیز دستوری وجود دارد که میتوان تابع خطای هر مقداری را محسابه نمود:
from math import *
erf (2)
>> 0.9953222650189527
erfc (2)
>> 0.004677734981047268
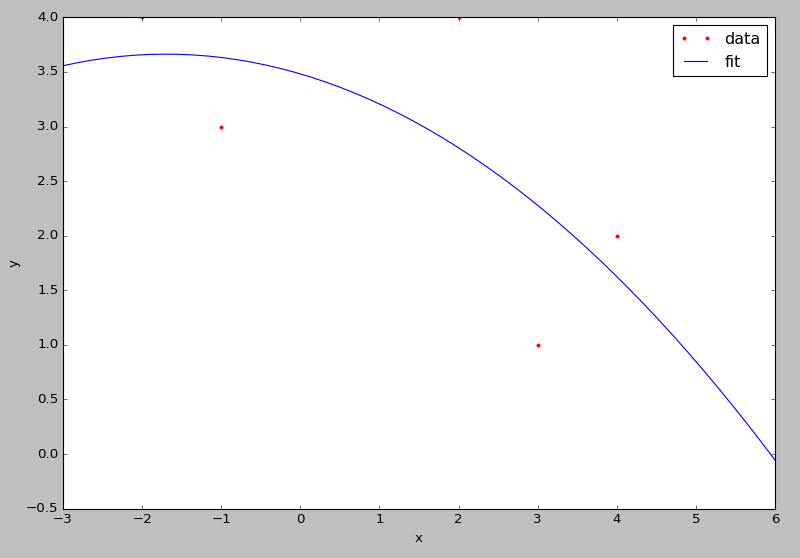
یکی از کاربردهای تابع خطا در درس چاهآزمایی میباشد. مثلاً گرینگارتن و همکاران با استفاده از توابع گرین (Green’s function)، معادله انتشار را برای یک چاه شکافدار (مدل شار یکنواخت) حل نمودند و به رابطه زیر رسیدند:
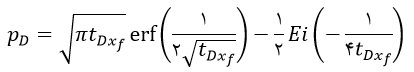
همانطور که مشاهده میکنید برای محاسبه فشار بیبعد در این رابطه، باید مقادیر تابع خطا را داشته باشیم.
۱ نظر
۰۸ شهریور ۹۶ ، ۱۷:۲۸